Thoughts on the New System of Big Data Analysis and Processing Technology
China Net/China Development Portal Network News After the information society enters the era of big data, people’s daily work and behavior, the working status of various online systems (such as information systems and industrial production lines), the signals of various sensors, and the records generated by navigation and positioning systems (global positioning system (GPS) and Beidou satellite navigation system, etc.) are routinely recorded into large-scale data as "experiences". Different from the scientific big data recorded and collected in the past to verify scientific theories and conjectures, recording these large-scale data did not have a clear scientific goal at first. However, they create other opportunities. People can find and summarize the laws through these data, and improve the efficiency of the system according to these laws, and can also predict and judge the future trend, and even help make more scientific and rational decisions. This process relies on big data analysis and processing technology. Therefore, big data analysis and processing technology aims to realize the value conversion from data to information, information to knowledge and knowledge to decision-making by using data science methods and widely recorded data.
At present, digital economy has become an important connotation of social economy, data has become a key factor of production, and big data processing technology has more and more profound influence on the running state of the world. With more and more data being recorded, collected and stored, how to deeply understand the distribution law of data and efficiently mine the value of data has become a key problem to be solved in the intelligent era. According to the report of International Data Corporation (IDC), the global data volume will be about 44 ZB in 2020 and 175 ZB in 2025. Only 2% of these data have been retained, and only 50% of them have been used. It can be seen that the linearly improved data processing ability cannot match the exponential growth of data scale, which makes the "scissors difference" between them bigger and bigger. At the same time, in the huge data space, the core data that is really valuable for a specific task is often extremely sparse or incomplete. The above phenomenon is the coexistence of data flooding and high-value data loss.
Intelligent applications represented by enterprise services on the Internet platform mostly adopt the big data analysis and processing technology supported by "big data+big model+big computing power", which mainly increases the data processing scale and improves the computing performance through system optimization, thus effectively solving some relatively low-order complexity prediction and judgment problems, such as image classification, voice recognition, structure prediction, and well-defined man-machine game. However, in an open and complex system environment, the data is dynamically generated and evolved, and there are huge uncertainties and variables that affect the running state of the system, which makes it difficult to directly model some high-order complex problems, or the approximate solution results are not credible, such as financial risk prediction, personalized intelligent diagnosis and treatment, and automatic driving in an open environment. In these high-order complex real systems, the data collection and distribution are often unstable and incomplete, which poses a new challenge to the big data analysis and processing mode that requires accurate discrimination.
At the same time, it is urgent to solve the problem of data and algorithm security. In the process of data circulation and sharing, data abuse and privacy leakage are faced. The data itself may also introduce the deviation existing in the real world, or the data is polluted under the counter attack, which makes the big data analysis model make biased and wrong decisions. At the moment when big data analysis and processing technology is gradually applied to key fields, how to make big data technology serve all fields in a safe and credible way is another difficult problem that big data development must face in the future.
This paper first reviews the development status of big data technology in recent 10 years, and in view of the challenges such as the coexistence of data flooding and data loss, the complex uncertainty of big data analysis and judgment, and the lack of data security, this paper puts forward a new paradigm of big data analysis and a new framework of safe and credible big data processing, and explores a new model of big data supporting intelligent applications. On this basis, a new generation of big data analysis and processing software stack is proposed, and the traction demand and major applications under the new technology system are prospected.
Current situation of big data analysis and processing
In the past 10 years, with the strong promotion of all walks of life and the government in Industry-University-Research, the big data technology architecture, ecological environment and big data applications in all walks of life have developed rapidly.
Big data technology architecture
Massive data promotes the development of big data technology architecture. Big data management technology. Traditional relational database (SQL) mainly deals with less data and smaller scale of concurrent access, and there are a lot of operations to read and write hard disks and log records, so it is difficult to expand horizontally and cannot meet the data management requirements of Internet applications. In order to realize more data management, larger-scale concurrent access and more diverse data patterns, various non-relational databases (NoSQL) and distributed relational databases (NewSQL) which are reconstructed from the bottom are developing rapidly. Among them, NewSQL maintains the characteristics of traditional database supporting transaction processing, correctly executing four elements (ACID) and SQL standard query, and has the same excellent scalability as NoSQL. Big data processing technology. According to the different processing requirements, there are many different parallel computing models, including batch processing represented by Hadoop and Spark, high real-time stream processing represented by Spark Streaming, Flink and STORM, mixed stream and batch processing represented by Apache Beam and Lambda, and graph processing represented by GraphX and Apache Giraph. At the same time, the explosive demand of graph data and real-time data processing also promotes the integration of graph stream processing modes. In addition, computing hardware has gradually developed into a variety of computing units (such as CPU, GPU, NPU, etc.).The heterogeneous computing system and the multi-level integration of new hardware and software further improve the efficiency of big data processing. Big data analysis technology. The demand for analysis has gradually changed from small-scale, single-source and single-modal data statistical mining analysis to complex heterogeneous correlation of massive, multi-source and multi-modal data. The rapid development of deep learning technology has promoted the ability of big data analysis model. Neural network model returned to people’s field of vision after winning the first prize in the computer vision target recognition project ImageNet competition in 2012, and then a series of breakthrough works were born, including knowledge map providing knowledge service, generating real data against network synthesis, AlphaGo defeating human beings, GPT-3 pre-training language model and so on. In addition, the increasingly mature deep learning frameworks (such as TensorFlow, PyTorch, Flying Paddle, etc.) have also lowered the threshold for using deep learning to analyze big data.
Big data application
In recent years, the rapid development of big data analysis and processing technology has spawned many big data applications and empowered the intelligent development of a large number of industries. Some iconic applications have subverted traditional information technology capabilities in terms of modes and capabilities. Scientific discovery. Alpha-fold of DeepMind Company can predict the three-dimensional structure of protein based on protein’s gene sequence data, and then analyze the properties of protein, which helps biology to make great progress. Digital economy. The rise of e-commerce platform connects consumers and suppliers all over the world. Through the accurate analysis of transaction big data, it improves transaction efficiency, promotes the use of online payment and digital currency, and subverts the mode of social credit reporting; Financial risk judgment based on big data, microfinance and inclusive finance have also promoted the prosperity of the digital economy. Social security. China uses big data methods to assist social governance and decision-making in the fields of public health and finance; The United States tries to study the role of big data technology in solving social inequality and making urban policies. Life and health. Based on a large number of academic papers and clinical trial results, Britain has developed a variety of drugs to cure motor nerve recession, as well as digital contact tracking technology widely used by countries in recent two years, which has helped predict the spread speed and trend of the epidemic, and was listed in the "Top Ten Breakthrough Technologies in the World" in MIT Science and Technology Review in 2020 and 2021 respectively. The application of big data technology at home and abroad has changed the time-consuming and labor-intensive working methods in many traditional industries.It has achieved fruitful results in intelligence and efficiency.
Ecological construction of big data
The prosperity of big data analysis and processing is inseparable from the technological ecological development formed by large-scale data resource sharing, open technical architecture and open source algorithm model. Open source data. Open source data supports the construction of various big data technologies. For example, ImageNet, a visual data set released by Stanford University in 2009, Mimic-III, a large-scale medical information database released by Massachusetts Institute of Technology in 2015, and Open Graph Benchmark, a graphic data set released by Stanford University in 2020, all greatly influenced the development of big data technology. Open source software. Apache Software Foundation has released a complete set of distributed storage and processing framework Map-Reduce, linear algebraic computing framework Mahout, machine learning library MLlib, etc. based on Hadoop ecology, aiming at enabling developers to quickly realize and apply big data analysis and processing algorithms. Since 2014, open source frameworks of deep neural networks, such as Caffe, Tensorflow and PyTorch, have provided important support for learning intelligent models for different tasks from big data. Open source model. Pre-training language models such as BERT and GPT3 based on large-scale data learning greatly reduce the application cost of related technologies and broaden the downstream application scenarios. In addition, how to ensure data security and personal privacy has recently been highly valued by governments and organizations all over the world. Therefore,Further exploration is still needed to balance technology development and data security, balance efficiency and risk, and establish a good big data ecological environment.
New Generation Big Data Analysis and Processing Requirements
At present, for large-scale heterogeneous data sets, the mainstream big data analysis and processing method is to constantly try ultra-large-scale model parameters under the general model framework to achieve "end-to-end" analysis and inference. In this mode, the ability of big data analysis and processing depends largely on the support of computing platform and data resources. In practical application, these big data analysis and processing technologies are faced with challenges such as the coexistence of data flooding and missing in real scenes and key areas, the complex uncertainty of big data analysis and judgment, and the lack of data security supervision, which ultimately leads to problems such as poor interpretability of the analysis and processing process, weak model generalization ability, unclear causal laws, unreliable judgment results, and low data value utilization rate. In order to solve these challenging problems, we need to rethink the architecture and analysis mode of big data processing. The new generation of big data analysis and processing technology system should realize high-value knowledge generation, continuous online instantaneous decision-making, safe and credible reasoning and judgment, and be suitable for all kinds of online system action optimization in the future. This paper believes that the new generation of big data analysis and processing needs to meet at least the following four requirements.
Computational paradigm of human in the loop. In order to solve the high-order complex problems that the existing big data analysis and processing methods are difficult to overcome, it is necessary to introduce human intelligence and decision-making, and emphasize the organic interaction among people, machines and data. Different from the original human-computer interaction, that is, the machine follows human instructions or people listen to the output results of the machine, but pays more attention to the deep integration calculation of human brain and machine thinking.
Analysis mode of broad-spectrum correlation. In order to solve the problems of low value density, sparseness, inhomogeneity and lack of key information of big data, on the one hand, multiple heterogeneous signals left by various objects in the multi-domain and multi-dimensional data space of "man-machine-object" fusion are merged, and the signals are enhanced by correlation; On the other hand, we should integrate data and knowledge, build a lifelong learning, transportable and expandable knowledge system, and form a new analysis mode of deep integration of data-driven and knowledge-guided.
Online enhanced processing architecture. With the development of the Internet of Everything and the ubiquitous intelligence, collaborative computing technology and decoupled cloud-side processing framework of big data cloud have become hot spots. Based on the cloud computing environment, the mixed processing of streams and batches will further develop to the edge, and training, learning and reasoning and prediction will be integrated in the front-end equipment. Using the flexible scheduling ability of cloud edge resources, we can realize the pre-positioning of perception and cognition, and support instantaneous decision-making based on dynamic active data in online environment, thus forming a decentralized, heterogeneous and continuous online computing framework.
Secure and credible big data analysis. Security and trustworthiness are the basic requirements to meet the cognitive and decision-making security in key fields and scenarios. On the one hand, focus on the interpretability, credibility and fairness of big data analysis and processing results; On the other hand, it realizes the security protection and anomaly detection of data in collection, storage, use and circulation, and ensures the robustness and immunity of analysis and processing models and methods under strong confrontation attacks.
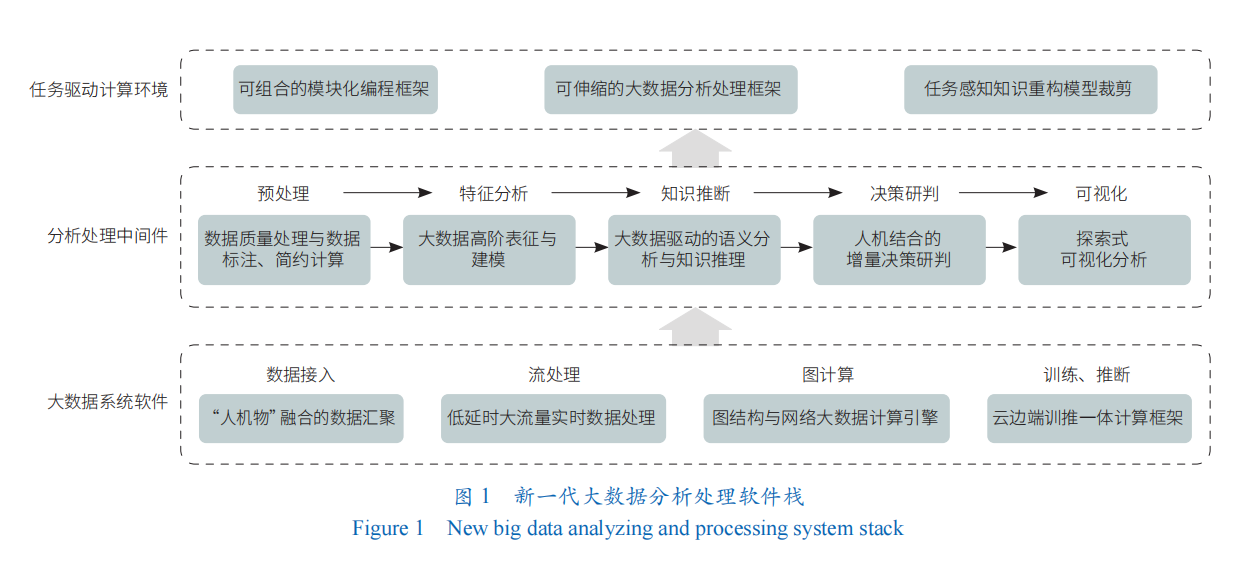
A new generation of big data analysis and processing software stack
Under the goal of efficient big data value extraction, safe and credible analysis and processing, in view of the above four important requirements of big data analysis and processing, it is urgent to establish a new system of self-reliant big data analysis and processing technology in the future, and develop a new generation of big data analysis and processing software stack (Figure 1), which is studied from three aspects: the underlying data operating system, the general analysis and processing middleware, and the business-driven computing environment and framework.
Full-stack Big Data System Software
Develop and cover big data system software in many aspects, such as data access, streaming processing, graph calculation, training and promotion.
Data access. Aiming at the problems of various data sources, mixed data types and low storage efficiency of heterogeneous data in the current data collection process, this paper studies the data aggregation and fusion method of "man-machine-object" integration, supports the collection and fusion of structured and semi-structured data from various data sources, explores efficient storage algorithms, improves the utilization efficiency of the underlying storage space, supports the efficient compression and restoration of data, and realizes the efficient perception, collection, fusion and storage of multi-source heterogeneous data in the "man-machine-object" ternary data space.
In terms of streaming processing. There is a single calculation mode in the existing big data processing framework, that is, pursuing large quantities or strong timeliness alone. In order to solve this problem, we will study the streaming processing framework of multi-computing mode integration, support batch processing, streaming processing, graph processing and other computing modes, and realize data processing with low delay, large flow and strong timeliness to cope with the continuous access to high-speed data streams.
Computational aspects of associated data. The existing computing framework is difficult to adapt to the characteristics of strong data dependence, high random access and non-uniform power law distribution of graph structure data. In order to solve this problem, this paper studies the computing engine for graph structure and network big data, puts forward a new distributed computing framework and parallel computing mechanism for large-scale graph data, customizes the query language standards and specifications for large-scale graph data, and realizes the standardization of graph query and graph analysis languages.
Training reasoning. The existing cloud big data processing architecture is difficult to meet the real-time and computing resource requirements of large-scale services. In order to solve this problem, this paper studies the integrated framework of training and reasoning in cloud-side collaboration, which pushes the training and inference process in big data analysis and processing from the cloud to the edge, supports the integration of training and pushing, provides services and performs calculations at the edge of data generation, and realizes "cognitive pre-positioning" and lifelong learning to provide distributed, low-delay, continuous online intelligent services and instantaneous decision-making.
Reconstruct the process of big data analysis and processing
From preprocessing, data representation, semantic analysis and knowledge reasoning, decision-making and judgment to visualization, the whole technology chain is upgraded and innovated.
Data quality processing and simplified calculation. For data quality processing, swarm intelligence technology can be developed to mine high-quality data and realize large-scale data acquisition and processing in a low-cost and efficient way; In terms of simplified computing, we can study the approximate computing theory and optimization algorithm framework based on data complexity, so as to guide people to find the basic method of computing-oriented data kernel or data boundary and build a model with efficient computing ability.
High-level representation and modeling of big data. Explore the theory and method of data representation learning based on unsupervised pre-training, extract high-level semantic abstract data representations from large-scale unlabeled corpus data, and improve the generalization ability of semantic representations; The pre-training and fine-tuning model based on small sample data is studied. Based on the data representation obtained from large-scale unsupervised corpus training, a universal high-quality data representation is constructed to assist upper-level tasks. Explore the theory and method of pre-training data modeling based on domain knowledge, integrate human knowledge into the pre-training model, and improve the learning efficiency of the pre-training model. At the same time, in order to cope with the knowledge gap caused by multi-source heterogeneity of data, it is necessary to further develop cross-modal data representation and modeling and multi-source knowledge fusion technology to realize the joint and utilization of global knowledge.
Semantic analysis and knowledge reasoning driven by big data. Study the semantic fusion method of big data oriented to fine-grained semantic units, and significantly improve the effect of association fusion of multi-source heterogeneous data; Study the mechanism and method of domain knowledge acquisition, large-scale common sense acquisition and understanding, and man-machine cooperation in knowledge acquisition in sparse sample environment, improve the ability of knowledge acquisition and greatly increase the scale of knowledge base; This paper studies the interpretable analysis method based on knowledge map, and the new semantic analysis method of deep integration of data-driven and knowledge-guided, which significantly improves the effect and interpretability of various models driven by knowledge.
Incremental decision-making and judgment of man-machine combination. In the future, a large number of physical devices, unmanned devices and human brains will be "online" and "interconnected" through ubiquitous networks, providing basic material conditions for human participation. As a natural system with intelligence, how to participate in the system loop of machine intelligence is a key problem. In the future, we should focus on solving the problem of thinking fusion or decision fusion, explore a new data science theory that human brain data and machine intelligence system information can be transformed each other, and design a high-efficiency calculation method. The current algorithm model will not continue to learn with the generation of data, that is, it cannot cope with the continuous and unexpected changing environment, especially in mission-critical applications. Therefore, it is necessary to study continuous learning, online learning and other technologies to realize continuous online instantaneous decision-making of algorithm models.
Exploratory visual analysis. Study a new visual interaction theory across subjects (people, machines and things), build a hybrid active visual analysis paradigm of multi-person collaboration, support multi-people to explore the same or different visual views from multiple angles at the same time, and design corresponding visual expression and interaction forms; This paper studies the cognitive computing and aggregation understanding model, method and core technology around big data visualization, and constructs the key technology of human-computer collaborative intelligence and its automatic understanding of big data visual content and attributes; Improve the computer automatic understanding, representation and generation capabilities around big data visualization, and build a visual computing and interaction technology system for big data.
Establishing a Task-Driven Big Data Computing Environment
From three aspects: combinable modular programming framework, scalable big data analysis and processing framework, and task-aware knowledge reconstruction model cutting, it provides a better and more flexible analysis and processing environment for all walks of life with scene awareness and consensus awareness.
Modular programming framework that can be combined. In the future, we can develop an extensible and reconfigurable agile development framework for multi-services, build a multimodal analysis pattern library and an intelligent business programming framework, break through the correlation analysis and holographic display of multi-source heterogeneous data, realize the high-level abstraction of data, algorithms and models, form an intelligent combination analysis operator library supporting task-oriented scenarios, realize the endogenous support of intelligent algorithms, and empower interactive collaborative analysis of human-computer mixing.
Scalable big data analysis and processing framework. In the future, a processing framework supporting flexible computing, scalable model and flexible configuration can be developed, that is, various tasks can be divided according to the actual application task scenarios and the requirements of computing resources to meet specific requirements, accuracy requirements, delay requirements, real-time requirements, etc. At the same time, a scalable big data analysis and processing framework is constructed, which can flexibly allocate computing resources and data scale to achieve flexible adaptation.
Task-aware knowledge reconstruction and model clipping. In the future, we can develop task-oriented advanced knowledge computing language and model clipping technology, realize knowledge reconstruction for specific domain tasks based on general knowledge map, and establish a knowledge computing engine integrating common sense and domain knowledge, which can significantly improve the ability and efficiency of knowledge management and utilization.
Suggestions on Promoting the Development of New Generation Big Data Analysis and Processing Technology
Establish a theoretical basis. The establishment of a new system of big data analysis and processing technology is inseparable from the breakthrough of basic theory. Establish the theory of data complexity and big data computability. Regression data origin, explore the regularity of data distribution, structure rules and space-time scale, so as to design an efficient calculation method. Explore the big data analysis theory of heterogeneous broad-spectrum correlation. The weak signals left by various targets in the multi-dimensional data space of "man-machine-object" fusion are correlated and amplified, and the convergence theory of instantaneous decision inference method in wide-area open-loop and non-uniform dimensional environment is studied. Study the theory of security and credibility of big data analysis and processing. On the one hand, study the theory of data security sharing and privacy calculation to ensure the security in the process of data circulation sharing; On the other hand, the inherent deviation of data and the robustness limit and verifiable theory of analysis and processing when data is attacked are studied, and a mechanism that can be prevented, audited and held accountable is established to ensure the credibility of analysis and processing results in a strong confrontation environment.
Increase the application of traction. The new big data analysis and processing technology system should be able to fully and efficiently empower industries, industries and security fields. At the same time, it is also necessary to use tractive application scenarios such as scientific discovery, life health and social governance to promote the healthy and benign development of the new system of big data analysis and processing. Scientific discovery. With the help of big data analysis technology, this paper discovers scientific laws from a large number of experimental data and forms a new scientific research methodology based on big data analysis. Life and health. Research on big data methods to assist the discovery of complex compound molecules, reduce the research and development cost of new drugs, accelerate the improvement of comprehensive medical level, and use big data means to deal with major epidemics and events efficiently and continuously online. Social governance. Give full play to the advantages of big data technology in multi-party complex related problems and social group cognitive modeling and analysis, and build an artificial intelligent decision-making system to realize scientific government decision-making, accurate social governance and efficient public services.
Data governs the ecological environment. The application and development of big data technology cannot be separated from benign data governance and technological ecological construction. Personal privacy protection. It needs corresponding laws and regulations to regulate it. For example, in 2016, the European Union introduced the General Data Protection Regulations to help citizens control personal privacy data; In 2021, China issued the Data Security Law of People’s Republic of China (PRC) and the Personal Information Protection Law of People’s Republic of China (PRC), which gave reasonable control and supervision to the collection and use of big data. Ensure the safe circulation and sharing of data. It is necessary to establish rules and regulations for data circulation, optimize systems related to data sharing, trading and circulation, clarify the distribution of data ownership, explore the data trading market, and build an orderly data circulation environment.
To sum up, in the future, we should develop and break through the general model architecture, analysis model and calculation paradigm, and establish a new architecture, new model and new paradigm, as well as a safe and credible new system of big data analysis and processing technology; Build a new generation of big data analysis and processing software stack; Research and develop corresponding theories and practice traction application; Establish a benign data governance ecology and promote the continuous progress and leap-forward development of big data analysis and processing technology.
(Author: Cheng Xueqi, Liu Shenghua, Zhang Ruqing, Institute of Computing Technology, Chinese Academy of Sciences, School of Computer Science and Technology, University of Chinese Academy of Sciences; Contributed by Journal of China Academy of Sciences)